-
General
-
Releases
-
Base Connector
-
- Beginner's Guide
- Overview
- Stations
- Datamaps
- Importing templates
- Formats
- Setting conditions
- Placeholders
- Job filter function
- How to create backups
- Running and Monitoring Jobs
- Export Job Automation
- Import/Export & copy of data map rows
- Synchronizing references that are not contained in views
- Get the preconfigured "Source data set - Template"
- Configuring categories and products
- Channel/View Tree Maintenance Active Job
- Configuring the price & stock modules
- Configuring the price/stock value ranges
- Configuring volume discounts/scale prices
- How to export prices
- How to export stock values from certain storage units
- Use of Contentserv Credentials
- Connector & Station User Limitation
- SC::Dynamic Image Crop Preset
- Todos
- Show all articles ( 11 ) Collapse Articles
-
- Price Table
- Stock Table
- Sales Channel Table
- Complex Article Table
- Importing data into SAWS tables (price, stock, etc.)
- SAWSConnector Usages
- Variant Articles
- Assignment of articles to complex articles
- Searching for SC::Prices / SC::Stocks
- Searching for SC::Channels
- Setup a transformation list for CSTypes
- Context-Sensitive Product Value Export
-
- Working with placeholder in conditions
- Improve usability of SC::Tables
- Placeholder for SC::Price, SC::Channel, SC::Stock
- REST Service API for SAWS Tables (Prices, Stock, Channels & Complex Articles)
- Dataflow import of SC::Tables
- Dataflow export of SC::Tables
- The datamap summary - Creating an automated documentation
- Export images as a ZIP file
- Image export with direct access to the CONTENTSERV platform
- Image export with no access to the CONTENTSERV platform
- Image export from a third party system
- How to configure CS Dashboard
- Setup a transformation list for CSTypes
- FAQ
- Export Smart Document via Active Script and assign output to product
- Format Macros
- Controlling Connector Jobs via the REST API
- Sales Channel Maintenance via Excel Cross-Reference
- Sales Channel Inheritance Active Job
- Job Parameters & Context Parameters
- Logbook
- Fill complex article tables automatically
- Datamap Mapping Status
- Show all articles ( 8 ) Collapse Articles
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for CS type reference
- Loop values for a CS table
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Owl Cloud Services
-
Owl Data Hub
-
Ursula AI
- Ursula AI
- Supported AIs
- AI Value Transformation Format
- AI Value Translation Format
- Generate Descriptions with Ursula AI Active Job
- Populate Attributes via Ursula AI Active Job
- AI Product Tree Organizer Active Job
- Mapping Sales Channels via the Ursula AI Active Job
- Store value into a Contentserv Item
-
GenericJSON / DynamicJSON Connector
-
- SAWSConnector settings
- Categories
- Products
- Product-Category assignment
- Export von Feldkonfigurationen/Attribute/Wertelisten
- Finish the export
- Response log
- Sample JSONs
- SQL Transmitter
- Shopify Transmitter
- Base. (Baselinker) Transmitter
- PlentyONE Transmitter
- Building JSON Target Keys
- Default HTTP Transmitter
- Configuratorware Transmitter
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Response Handler Field Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 6 ) Collapse Articles
-
GenericXML Connector
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
SimpleExcel Connector
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Magento Connector
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Shopware 5 Connector
-
- Configuration Shopware
- Configuration PIM
- Shopware attribute setting
- Configuration SAWSConnector
- Station configuration
- Source data set configuration
- Configuring categories and products
- Price table configuration for Shopware
- Result in Shopware
- Subshops and the SAWSConnector Shopware
- ean
- Custom Fields (attribute)
- highlight
- purchaseSteps
- stockMin
- supplierNumber
- notification
- shippingFree
- length
- height
- width
- weight
- shippingTime
- metaKeywords
- Show all articles ( 9 ) Collapse Articles
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Shopware 6 Connector
-
- Tutorial Video
- First steps
- Import Shopware settings
- Export categories
- Export media files
- Export simple products
- Export multiple languages
- Export variant products
- Export product properties
- Export custom fields
- Export product cross-selling relationships
- Export prices
- Export stocks
- Export into any other Shopware field
- How to address multiple Shopware 6 websites
- How to address different Shopware 6 Sale-Channels from one Contentserv System
- Useful Links
- Sales Channel Maintenance via Excel Cross-Reference
- Show all articles ( 3 ) Collapse Articles
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
OXID Connector
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Typo3 Connector
-
-
- Send value of a PIM reference
- Loop values for CS PIM references
- Send value of a Channel (view) reference
- Loop values for CS Channel (Views) references
- Send value of a MAM reference
- Loop values for CS MAM references
- Send value of an attribute reference
- Send value of a user reference
- Loop values for user references
- Send value of a reference (deprecated)
- Merge reference values format plugin
- Search for usage of item
- Search for item IDs using attribute data
-
- Loop Head and Loop Value
- Loop values for several attributes simultaneously
- Loop values for child elements
- Loop values for CS PIM references
- Loop values for CS Channel (Views) references
- Loop values for CS MAM references
- Loop values for user references
- Loop values for SC::Prices
- Loop values for SC::Stocktable entries
- Loop values for SC::Complex products
- Loop values for a CS table
- Loop values for CS type reference
- Loop value for simple data record
- Loop values for JSON Objects
- Loop for value range entries
-
- Create a JSON-String (create an array)
- Format value lists
- Tree paths or values from tree elements
- Multistep formatting
- Send accesslevel of the object
- Send value of a job parameter
- Search for values in several attributes
- Format with PHP Code (deprecated)
- Format Macros
- Load data via REST Service
- AI Value Transformation Format
- AI Value Translation Format
- Store value into a Contentserv Item
- Execute a conditional format (switch-case) Format Plugin
- Load array value from the Contentserv getValues Format Plugin
- Process HTML table Format Plugin
- Replace via regex pattern format plugin
- Convert value ranges into each other
- Merge Array Format Plugin
- Export several attributes simultaneously
- Show all articles ( 5 ) Collapse Articles
-
Other Connectors
Move output file to predefined target
This functionality allows you to specify a target for your file output.
In this article you learn how to navigate the menus and define a target.
How to create a Job-Related Task
1) Go to Jobs (the so-called Jobcenter) in the SAWSConnector Suite.
2) Select Job-related rasks in the sub-menu.
3) And click on + (‘Add new task‘).
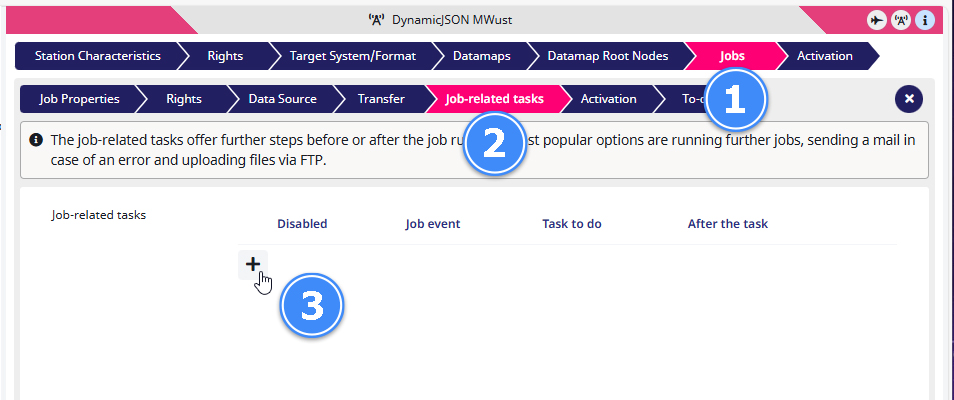
Another sub-menu opens where you can specify the basic conditions, for example when the task should start or what happens after the task is done. To learn more about this click on this link.
4) Click on the Task to do box and select ‘Move output file to predefined target‘.
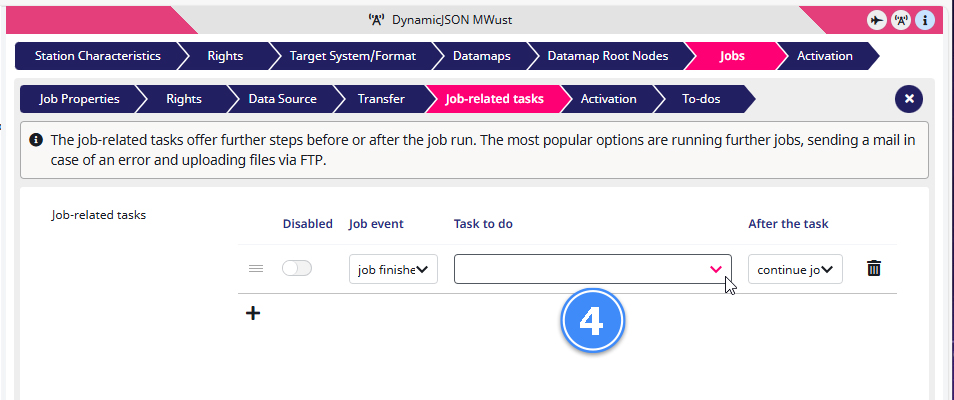
And the Settings menu will open.
Settings
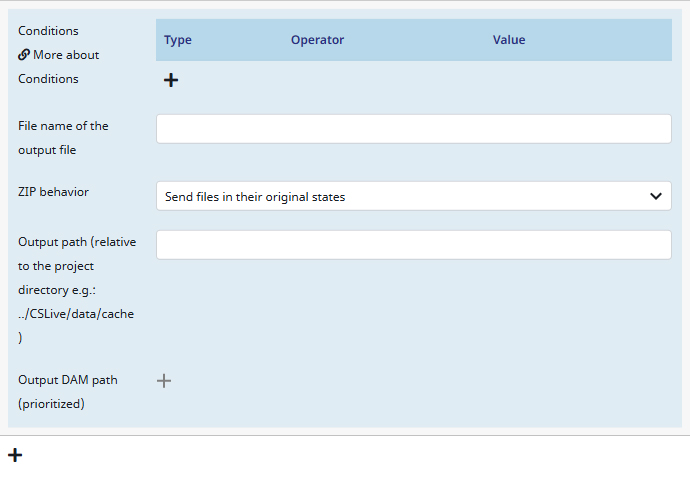
Conditions
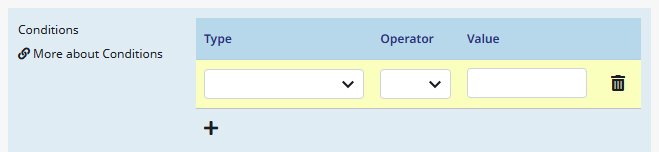
Allows you to specify even more conditions and context for the follow-up job. You can create a condition by clicking on + (Add new condition).
To learn about this functionality in detail, please click on this LINK.
File name of the output file
Allows you to define the name of the final output file.
Please note: The name box allows to use placeholders. You can find a list of all placeholders via this LINK.
ZIP behavior
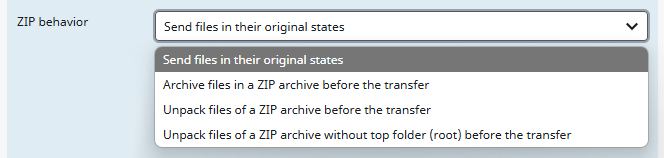
If you export more then one file the task will store them in a ZIP archive for easier management. This drop-down menu lets you select how the created ZIP archives should be handled.
You can either choose to leave the ZIP archives in their original states, archive or unpack them before the transfer or unpack them without the top folder (for example if there is only only folder inside it, making a top folder redundant).
Output path (relative to the project directory e.g.: ../CSLive/data/cache)
Allows you to directly determine an output path on your server.
It is recommended to always begin the path with: ‘../{your project name}/‘
Output DAM path (prioritized)
Here you can select the prioritized output directory for your DAM files inside the Contenserv Suite.
Run Example
To fully understand how you to select an output target it is best demonstrated with a case example.
My goal for this example is to give the job ‘Products‘ a target for its output.
1) I want to equip my ‘Products‘ job with the specific task so I just click on it to open it.
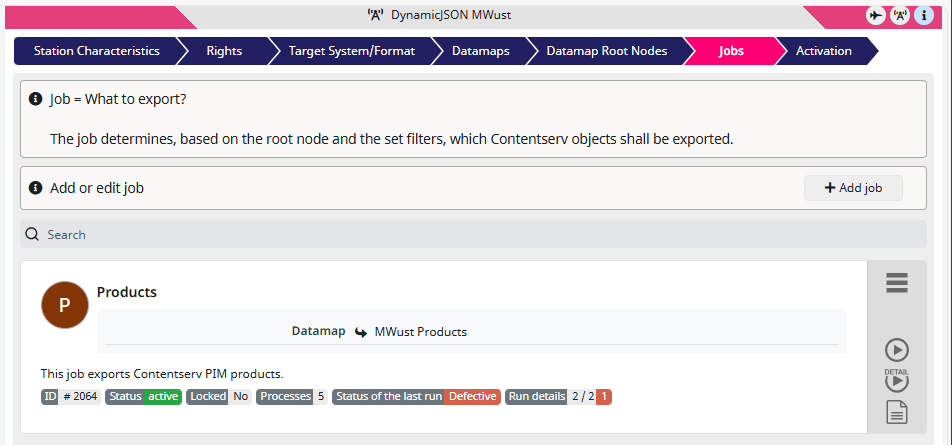
2) Inside the ‘Products‘ job, go to the Job-related tasks and create one by clicking on + (Add new task).
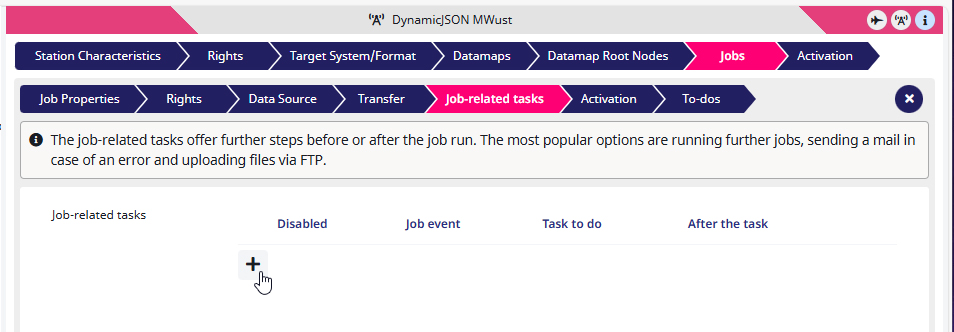
3) For a Task to do I select ‘Move output file to predefined target‘.
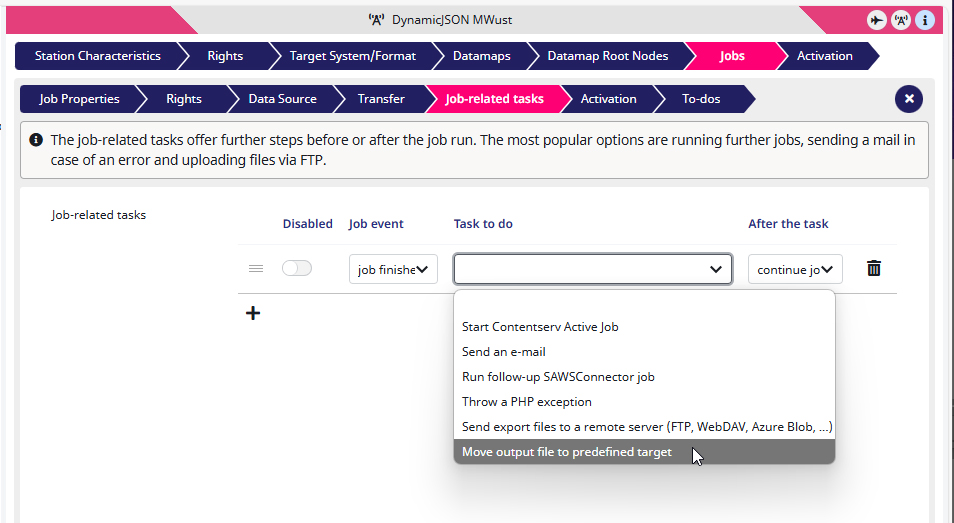
The Settings menu opens.
4) Since I don’t have any more Conditions to set, I’ll just ignore them.
5) For a File name I take ‘Output-file‘ since this is just a case example.
6) I order the ZIP behavior to leave the files in their original states.
7) Since I am giving the task an Output path for the DAM files, I just leave this box empty.
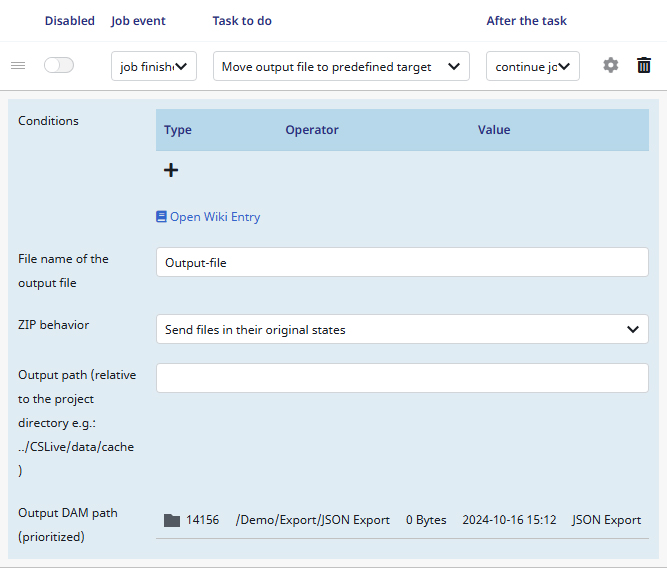
8) And for the prioritized Output DAM path I select ‘/Demo/Export/JSON Export‘. This is also possible by just typing the ID: ‘14156‘.
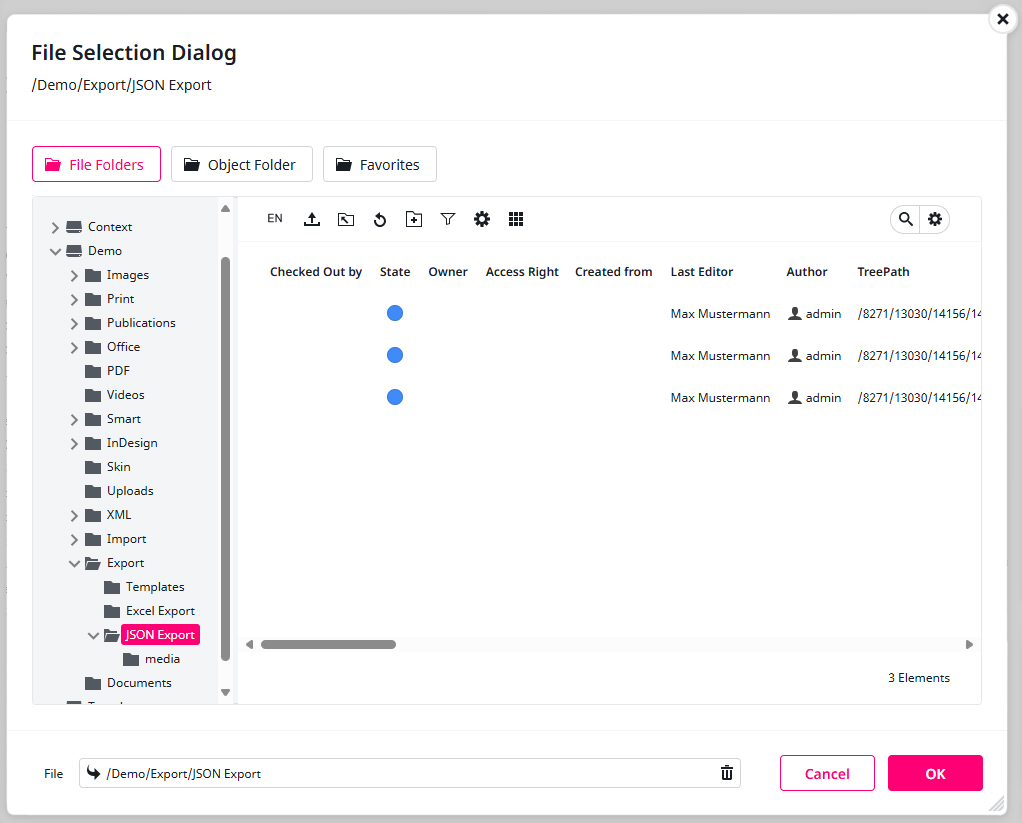
9) I save my progress right next to the tab tail below the Settings menu.

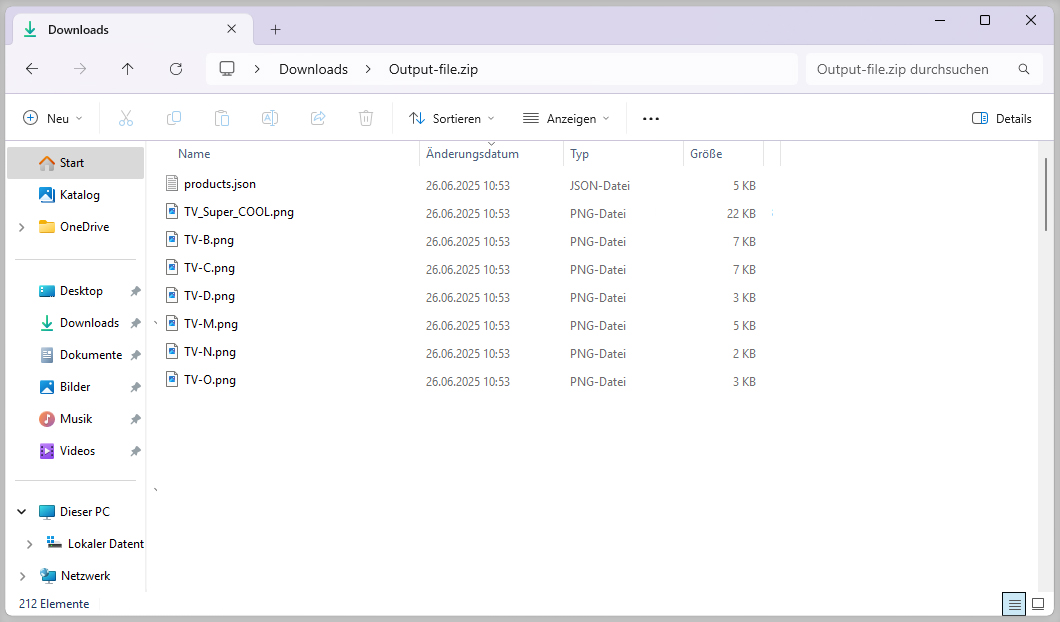
10) If the Connector job has multiple result files they will be archived as one ZIP file. If only the export JSON exists it will not be archived.
Since I configured a DAM file export via a Loop format in my Datamap, I have multiple result files which will be archived in a ZIP.
11) Last but not least I have to define which item should be exported, so I go to Jobs, then to Data Source and for the Root Node I select the ‘SLT 95 Nano Crystal (10254)‘ Smart TV
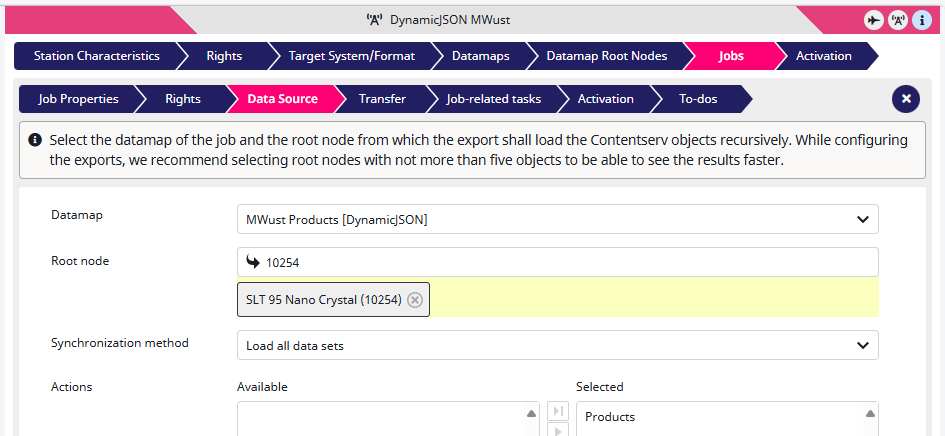
12) For the final step I launch the ‘Products‘ job.
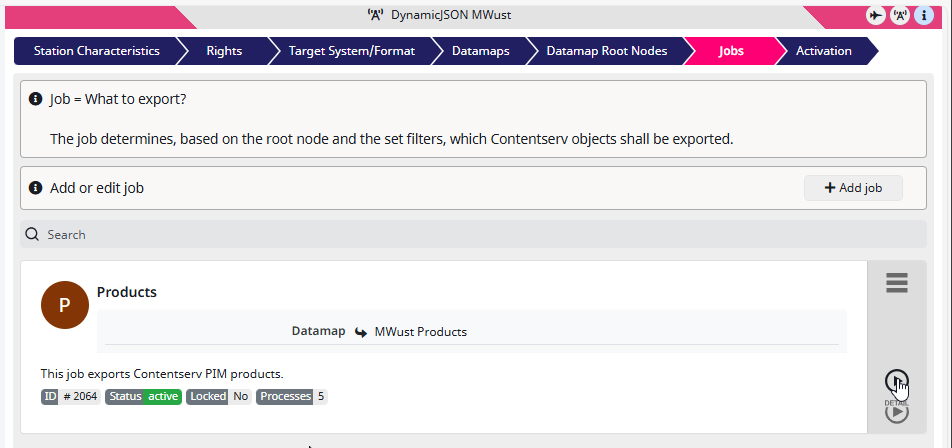
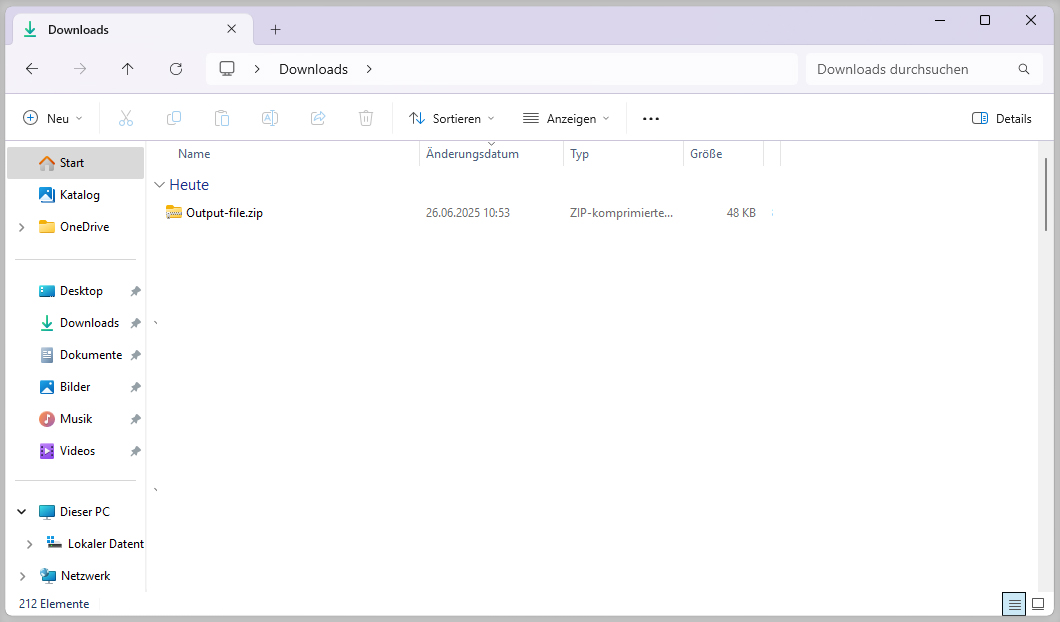
… and enjoy the results inside the DAM:
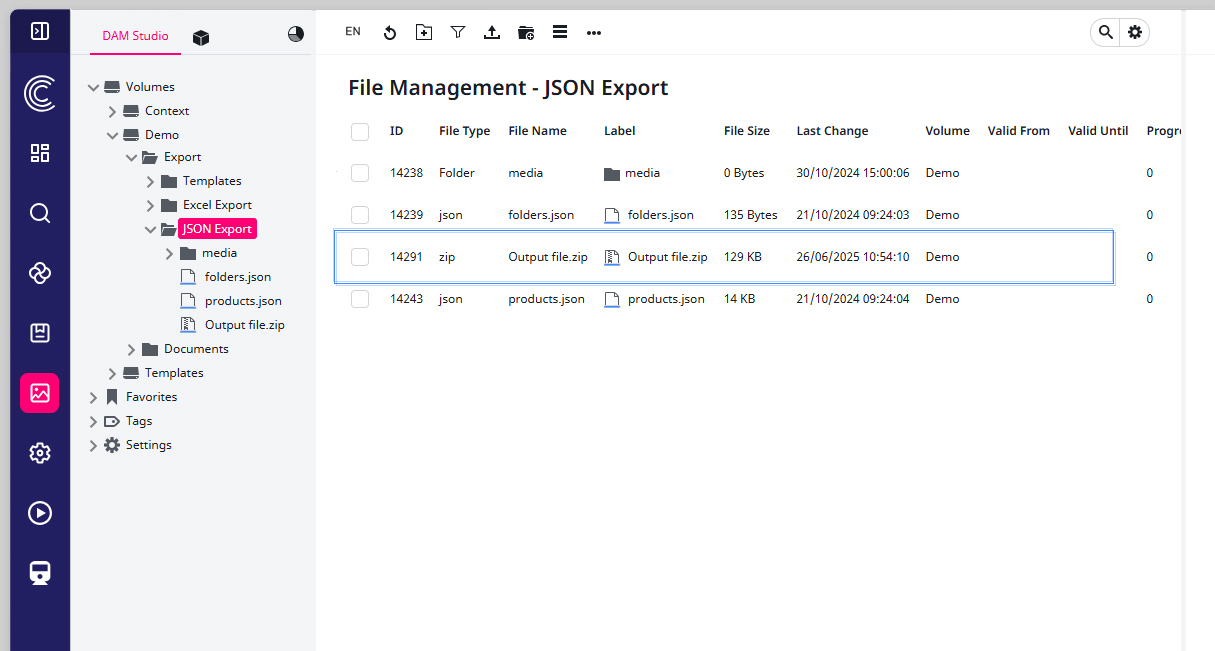
Also in my local Downloads folder: